本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
EAS(Elastic Algorithm Service)是PAI针对在线推理场景提供的模型在线服务平台。您可以将调试好的应用流一键部署至EAS,作为生产环境使用。本文为您详细介绍应用流的部署过程。
前提条件
已创建应用流,并完成调试。详情请参见应用流开发。
部署服务
按照以下操作步骤,将应用流部署为EAS服务:
登录PAI控制台,在右侧选择目标工作空间后,单击进入LangStudio。
在应用流页签,单击已调试完成的应用流名称,进入应用流详情页面。
单击应用流详情页面右上方的部署按钮。
说明仅当应用流的运行时已启动时,才能单击部署按钮,将其部署为在线服务。
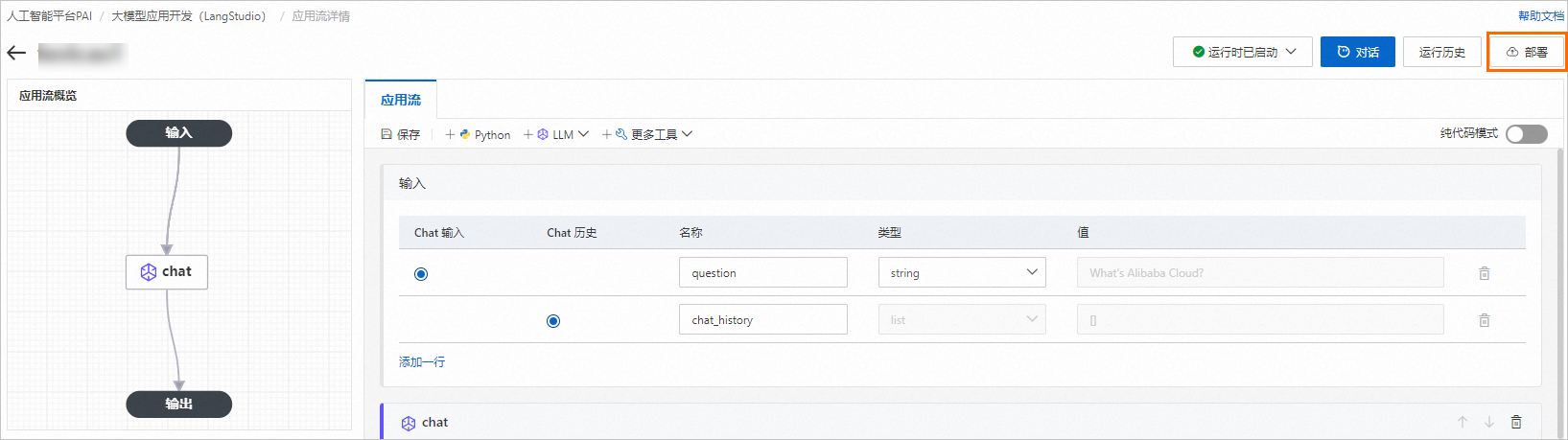
在部署配置面板中,配置以下关键参数,其他参数配置说明,请参见服务部署:控制台。
参数
描述
资源部署信息
资源组种类
实例数
建议配置多个服务实例,以避免单点部署带来的风险。
资源配置选择
建议您选择至少4核8 GB的机器规格部署应用流服务。如果您开发的应用流的代码对资源要求比较高,可以按需选择更高规格的配置。
专有网络配置
VPC
由于EAS在线服务部署在EAS资源组上,为确保服务部署后客户端能正常访问EAS在线服务,您可以选择专有网络连通方案,将客户端与部署服务的资源组间的网络连通。EAS服务内部默认与公网不通,如果您有EAS服务访问公网的需求,需经由VPC开通公网访问。详情请参见配置网络连通。
说明当在应用流中使用向量数据库连接时,请确保所配置的专有网络与相应的实例保持一致,或保证网络连通。
交换机
安全组名称
对话历史
开启对话历史
仅适用于对话型应用流的配置,提供多轮对话历史消息的存储与传递功能。
对话历史存储
如果您部署的服务为生产使用,建议使用外部存储,如阿里云数据库RDS。详情请参见对话历史
警告采用本地存储方案,不支持多实例部署,也不支持单实例扩容到多实例,否则会导致对话历史功能不正常。
参数配置完成后,单击部署,并按照控制台操作指引部署应用流。
说明部署应用流会产生EAS相关的资源费用,计费详情请参见模型在线服务(EAS)计费说明。
应用流服务部署成功后,默认会添加以下6个标签。后续,您可以在EAS服务列表中,通过默认标签查询应用流对应的模型服务;也可以在LangStudio列表页面,通过FlowId或FlowName查看该服务对应的应用流详情。
CreatedBy: LangStudio
DeployMode: SERVING
FlowId : flow-***
FlowName: ***
FlowServiceId: snap-***
SnapshotId: snap-***。
调用服务
在线调试
服务部署成功后,您可以通过在线调试功能,验证模型服务是否运行正常,具体操作步骤如下:
进入模型在线服务页面,然后在推理服务页签,单击LangStudio应用流服务操作列下的在线调试。
在在线调试请求参数区域,配置以下参数,调用模型服务。

在Body页签,配置请求参数。请求参数中字典的Key需要和应用流中的Inputs定义一致。
参数配置完成后,单击发送请求。
API调用
查询服务Endpoint和Token。
进入模型在线服务页面,单击目标服务名称,进入服务详情页面。
在基本信息区域,单击查看调用信息,然后在公网地址调用页签,获取服务Endpoint和Token。
向服务发送API请求。
支持使用以下三种方式:
cURL
部署的EAS应用流服务支持使用cURL命令进行远程调用。示例命令如下:
curl -X POST \ -H "Authorization: Bearer <your_token>" \ -H "Content-Type: application/json" \ -d '{"question":"who are u?"}' \ "<your_endpoint>"其中关键配置说明如下:
配置项
描述
-H "Authorization: Bearer <your_token>"
设置授权头。其中<your_token>需要替换为应用流服务Token。
-d '{"question":"who are u?"}'
指定了POST请求的主体数据。是一个JSON对象,包含一个键值对,即问题字符串。其中Key需要和应用流中的Inputs定义一致。
"<your_endpoint>"
表示API的完整路径。其中<your_endpoint>需要替换为应用流服务的Endpoint。
Python脚本
演示如何使用requests库向应用流服务发送一个POST请求,首先确保已安装该库。如果未安装,您可以通过运行
pip install requests命令来进行安装。参考以下代码示例来实现请求,参数为"question": "who are you?"。import requests import json url = "http://<your-endpoint-here>" token = "<your-token-here>" data = {"question": "who are u?"} # 设置请求头,包含您的token headers = { "Authorization": f"Bearer {token}", "Content-Type": "application/json" } response = requests.post(url, json=data, headers=headers) if response.status_code == 200: print("请求成功,返回结果:") print(response.text) else: print(f"请求失败,状态码: {response.status_code}")其中:
url:请将<your-endpoint-here>配置为应用流服务的Endpoint。
token:配置为应用流服务的Token。
data:表示请求的主体数据。是一个JSON对象,包含一个键值对,即问题字符串。其中Key需要和应用流中的Inputs定义一致。
SSE
通过Server-Sent Events(SSE,服务器发送事件)技术,服务器可向浏览器实时推送数据,适用于实时对话等场景,例如LangStudio大模型应用流中的对话场景。使用SSE调用API时,客户端(如浏览器)通常会建立一个HTTP长连接请求,服务器端则通过该连接持续地向客户端推送数据,直到连接关闭或出现错误。
应用流部署的服务支持SSE,您可以使用Python实现通过SSE调用带有Endpoint、Token以及参数的接口。示例代码如下:
说明仅当LLM节点作为应用流的输出节点时,才支持流式调用。
import requests import json url = "http://<your-endpoint-here>" token = "<your-token-here>" data = {"question": "who are u?"} # 设置请求头,包含您的token headers = { "Authorization": f"Bearer {token}", "Accept": "text/event-stream", "Content-Type": "application/json" } if __name__ == '__main__': with requests.post(url, json=data, headers=headers, stream=True) as r: for line in r.iter_lines(chunk_size=1024): print(line)其中:
url:请将<your-endpoint-here>配置为应用流服务的Endpoint。
token:配置为应用流服务的Token。
data:表示请求的主体数据。是一个JSON对象,包含一个键值对,即问题字符串。其中Key需要和应用流中的Inputs定义一致。
查看Trace
在调用服务后,系统将在链路追踪页面自动生成一条Trace记录。您可以通过Trace来评估应用流效果。
在模型在线服务(EAS)页面,单击LangStudio应用流服务名称,进入服务详情页面。
切换到链路追踪页签,查看服务下所有的Trace。
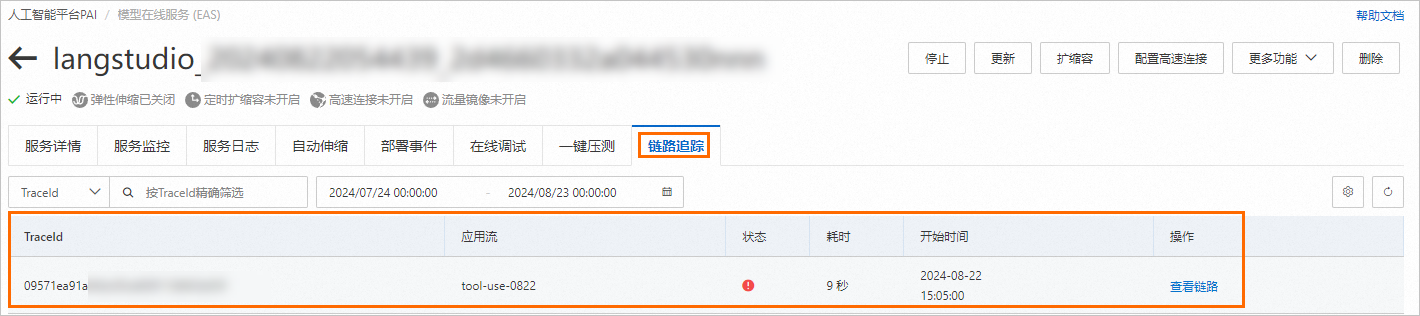
单击目标Trace操作列下的查看链路,进入Trace详情页面。
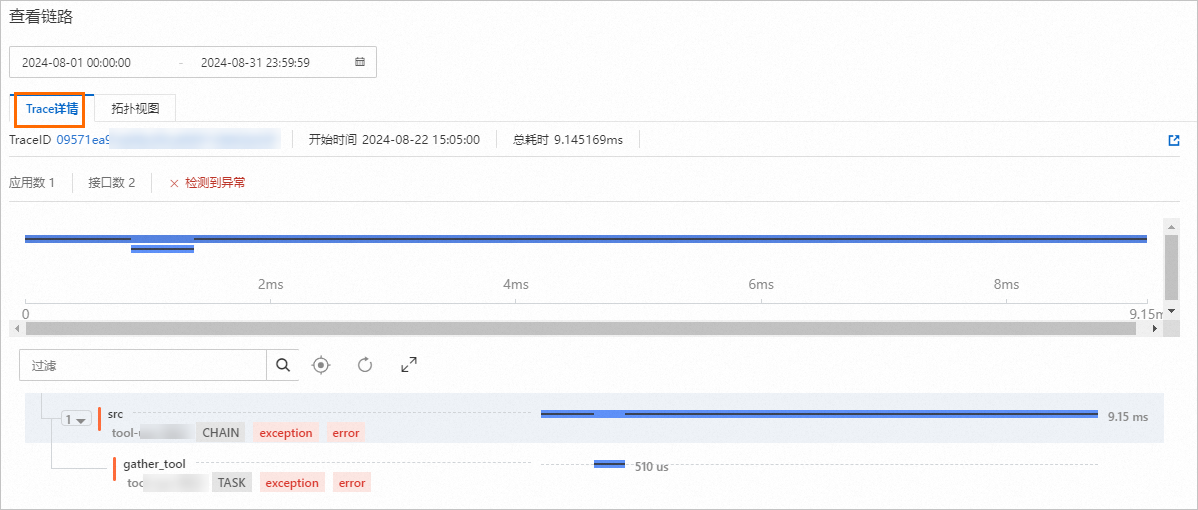
该页面提供的Trace数据支持您查看应用流中各个节点的输入和输出信息(例如向量数据库召回的结果),以及LLM节点的输入和输出信息。
对话历史
对于“对话型”应用流,LangStudio提供了多轮对话的历史消息存储功能。您可以选择使用本地存储或外部RDS存储来保存对话历史。
存储类型
本地存储:服务将利用本地磁盘,在部署应用流的EAS实例上自动创建一个名为
chat_history.db的SQLite数据库来保存对话历史记录,其默认存储路径为/langstudio/flow/。需要注意的是,在多实例部署环境中不支持此本地存储方案。请定期检查本地磁盘的使用状况,同时您也可以通过下文提供的API接口进行对话历史数据的查询与删除操作。当EAS实例被移除时,相关的对话历史数据也将一并被清除。云端存储:目前支持使用MySQL存储,您需要在部署服务时,为对话历史存储配置一个MySQL Connection,具体的配置方式请查看:连接管理-阿里云RDS-MySQL。服务将在您配置的MySQL数据库中自动创建以服务名称为后缀的表,例如
langstudio_chat_session_<服务名称>和langstudio_chat_history_<服务名称>,用于分别存储对话Session及对话历史消息。
Session、User支持
每一次对应用流服务的对话请求都是无状态的,当您希望多次请求被当作是同一个对话时,需要通过手动配置请求头的方式完成。服务请求方式详情请参见调用服务
请求头名称 | 数据类型 | 说明 | 备注 |
| String | 会话ID,每一次对服务的请求,系统会自动向本次会话分配唯一标识符,用以区分不同会话,并通过Response Header中 | 支持使用自定义会话ID,为了保证唯一性,会话ID规范为长度为32-255个字符,支持大小写字母、数字、下划线(_)、中划线(-)、英文冒号(:)。 |
| String | 用户ID,标识对话所属用户。系统不会自动分配,支持用户自定义。 |
对话历史API
服务也提供了对话历史数据管理API,您可以通过API方便地查看和删除这些数据。只需通过GET请求访问 {Endpoint}/openapi.json 即可获取完整的API Schema。该Schema是基于Swagger标准构建的,为了更直观地理解和探索这些API,推荐您使用Swagger UI对其进行可视化,使操作更加简单明了。
相关文档
部署及运行服务会产生EAS相关的资源费用,计费详情请参见模型在线服务(EAS)计费说明。